
I love the predictability of web apps. All of the interaction between the client and the server is predictable, observable, and often easy to recreate (curl, etc.). I also really like presentations, Slides, PowerPoint - pick your poison. I know Amazon would rather read a memo, but there's something about crafting a narrative in a set of slides that is really powerful.
Anyway. I've been using the Google Slides API for awhile now. Why? Check Part 3.
Today I want to take you through some exploration of the Google Slides API.
TL;DR of shortcomings I've seen:
- The
GETschemas for presentations and pages cannot be reused, as you might expect to natively be able to "create" slides. - The
presentations.createendpoint only creates blank slides. - You cannot change the page size via the API. This effectively means every programmatically generated slide is 16:9 (10" x 5.63")
- The only way to insert content onto slides is manually crafting a series of
batchUpdaterequests, which are often not 1:1 with theirGETrepresentations (meaning you must manually translate between these two schema expectations). - Custom shapes are not defined when reading in a
GETrequest, nor can they be meaingfully inserted with abatchUpdaterequest. This effectively means you can't programmatically insert icons, logos, etc unless it's a "standard" shape. - Text
pageElementsare returned with excess page breaks, which if directly translated into abatchUpdateproduce undesired results. Although you can fix this in your translation layer, it certaintly feels like a bug.
The takeaway? As of today, I would say the coverage of being able to reliably recreate slides is slightly too low to develop meaningful solutions around it.
Part 0: Intro to GSlides API
The API has two main constructs: presentations and pages.
Presentations are exactly what they sound like. A simple JSON schema that effectively defines a collection of pages, with some metadata like the presentation ID, title, etc.
{
"presentationId": string,
"pageSize": {
object (Size)
},
"slides": [
{
object (Page)
}
],
"title": string,
"masters": [
{
object (Page)
}
],
"layouts": [
{
object (Page)
}
],
"locale": string,
"revisionId": string,
"notesMaster": {
object (Page)
}
}Pages define each slide. There's some similar meta detail in the form of Properties, but the bulk of what is actually on the slide is pageElements . We'll talk about this element quite a bit later. When you're working with what I'll call "normal" slides, you mostly expect to see pageProperties and slideProperties.
{
"objectId": string,
"pageType": enum (PageType),
"pageElements": [
{
object (PageElement)
}
],
"revisionId": string,
"pageProperties": {
object (PageProperties)
},
// Union field properties can be only one of the following:
"slideProperties": {
object (SlideProperties)
},
"layoutProperties": {
object (LayoutProperties)
},
"notesProperties": {
object (NotesProperties)
},
"masterProperties": {
object (MasterProperties)
}
// End of list of possible types for union field properties.
}pageProperties only defines the background fill/ color.
slideProperties defines the layout and master slide that the current slide is based on. It also defines what your notes page looks like, namely how the printed page would be rendered or exporting with speaker notes. In 99% of slides, you get two pageElements that define placeholders for the slide image and any text. It's not obvious how this changes given the options for notes pages are defined in real time during the print preview process. This setting also is global, rather than per slide, so I remain a bit confused on the value in defining this for every slide.
There's a lot of other detail here about all of the elements that exist within a page, but that's for another day.
Part 1: Creating Slides the Easy Way?
I'll start with the biggest limitation of the API from my perspective:
presentation.get response right now cannot be used anywhere. This doubly means that the presentation.create method can't do anything except create a blank slide.Let me explain. Everything I discussed above in Part 0, which is effectively the structure of how Presentations and Pages are represented in JSON when you GET either a presentation or presentation.page, cannot be used anywhere. The schema for creating or modifying slides does not match the schema for how presentations and pages are represented programmatically. There are many similar parts, but you can't simply pass the response from presentation.get to presentation.create.
This isn't immediately obvious, because if you, like me, go read the presentations.create method, here's the request body schema:
{
"presentationId": string,
"pageSize": {
object (Size)
},
"slides": [
{
object (Page)
}
],
"title": string,
"masters": [
{
object (Page)
}
],
"layouts": [
{
object (Page)
}
],
"locale": string,
"revisionId": string,
"notesMaster": {
object (Page)
}
}Looks familiar doesn't it? Really makes it seem like you can/ should include the slides you want created. Don't miss this very important sentence:
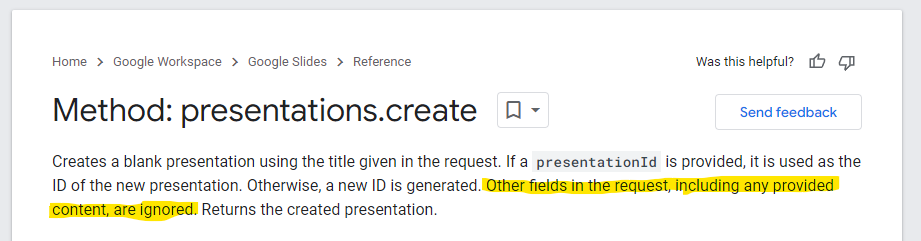
According to Google, this is intended. My first thought was when they rolled out the API in May of 2016, they hadn't implemented the rest of the create functionality yet, so the method was really more of a "create default blank slide". In 2018 (from the bug ticket), it took 4 years for Google to point out this was expected behavior. I won't hold my breathe this is changing any time soon.
Part 2: Creating Slides the Manual Way
Since we've learned above we can't actually use the presentations.create method to create slides with content, we'll need to rely on the batchUpdate method, which acts more as a transactional set of actions to take. Let's go through a few experiments so you can get a feel for how this works and the limitations.
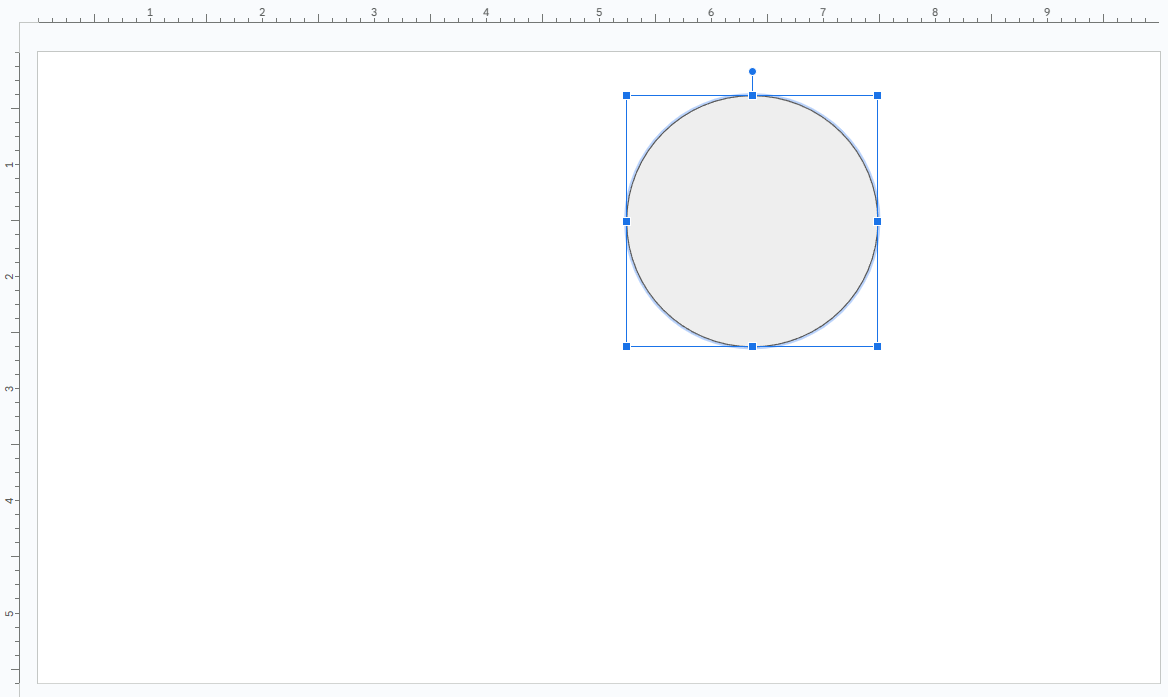
Experiment 1: Recreate a slide with a circle
Via the webUI, in a brand new presentation, let's create a circle:
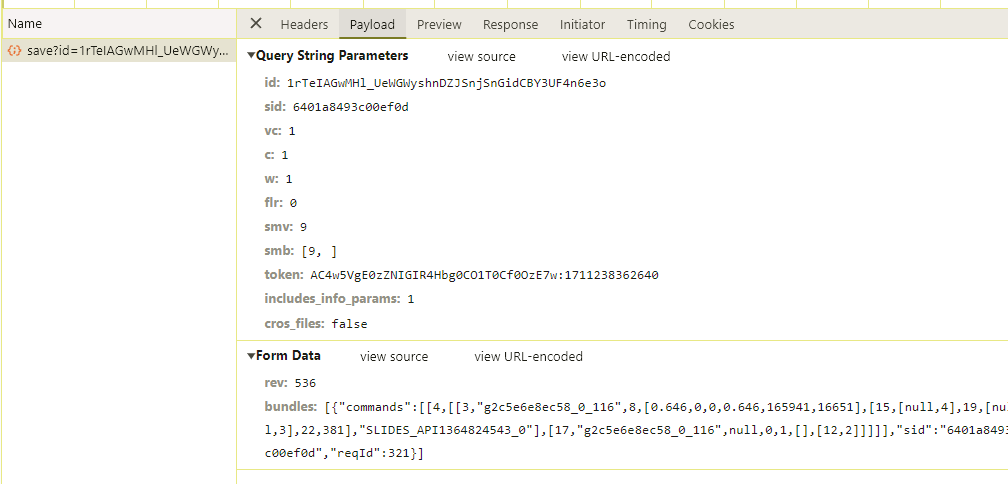
That is the only "action" I took, so I can see the resulting save request in the network console:
Here's an example of the bundles from a similar request also creating a circle:
[{"commands":[[4,[[3,"g2c5e29abb69_0_0",8,[0.6825,0,0,0.6825,191903,14229],[15,[null,4],19,[null,3],22,381],"p"],[17,"g2c5e29abb69_0_0",null,0,1,[],[12,2]]]]],"sid":"17fb4e261b6935cf","reqId":1}]
// Prettier...
[
{
"commands": [
[
4,
[
[
3,
"g2c5e29abb69_0_0",
8,
[0.6825, 0, 0, 0.6825, 191903, 14229],
[15, [null, 4], 19, [null, 3], 22, 381],
"p"
],
[17, "g2c5e29abb69_0_0", null, 0, 1, [], [12, 2]]
]
]
],
"sid": "17fb4e261b6935cf",
"reqId": 1
}
]bundles , inserting a circle into a SlideThis minified version of what is being saved is certainly cryptic. Let's park this for now, I'll come back to it in a second.
...
There's some other stuff in the query string parameters, but my hunch after testing this for quite some time, is that these parameters are not related to the action I just took, but rather just some meta data about the slide, my permissions, etc. Here's my best guess:
id: 1C4SjQ1EVPtMl9x5qkNtZUtSTzaegJy8JTk6R_BR5GyE, // presentation ID, can verify in URL
sid: 17fb4e261b6935cf, // session identifier?
vc: 1, // version? Perhaps used if a file is copied/ duplicated
c: 1, // collaboration flag? Unclear when this would be false
w: 1, // write flag? Assume this is related to permissions
flr: 0,
smv: 9, // state model version? Pure guess, seems like this is always 9 recently
smb: [9, ], // array of possible versions? Maybe used for phased rollouts?
token: AC4w5Vi6jWwLUI-uRlxxTzYPnsVIkcUIsA:1711227000756, // some auth token for the API with an appended UNIX timestamp? (although it'd be off by a few days)
includes_info_params: 1, // feature flag for more meta data?
usp: slides_web, // user service parameter? Basically where the request originates from; I don't see this key>value all the time.
cros_files: false, // flag related to compatibility across devices?...
Alright, let's go ahead and presentations.get that slide above via the API. I'll skip any detail related to setting up an application and granting permissions as I imagine this is the same for usage of any Google API.
Anyway, with the resulting response, I used a debug helper make the JSON a bit easier to navigate, and I went ahead and expanded everything under pageElements as this is where the circle is actually getting defined.
array:5 [▼
"objectId" => "p"
"pageElements" => array:1 [▼
0 => array:4 [▼
"objectId" => "g2c5e29abb69_0_0"
"size" => array:2 [▼
"width" => array:2 [▼
"magnitude" => 3000000
"unit" => "EMU"
]
"height" => array:2 [▼
"magnitude" => 3000000
"unit" => "EMU"
]
]
"transform" => array:5 [▼
"scaleX" => 0.6825
"scaleY" => 0.6825
"translateX" => 4797575
"translateY" => 355725
"unit" => "EMU"
]
"shape" => array:2 [▼
"shapeType" => "ELLIPSE"
"shapeProperties" => array:5 [▼
"shapeBackgroundFill" => array:1 [▼
"solidFill" => array:2 [▼
"color" => array:1 [▼
"themeColor" => "LIGHT2"
]
"alpha" => 1
]
]
"outline" => array:3 [▼
"outlineFill" => array:1 [▼
"solidFill" => array:2 [▼
"color" => array:1 [▼
"themeColor" => "DARK2"
]
"alpha" => 1
]
]
"weight" => array:2 [▼
"magnitude" => 9525
"unit" => "EMU"
]
"dashStyle" => "SOLID"
]
"shadow" => array:8 [▼
"type" => "OUTER"
"transform" => array:3 [▼
"scaleX" => 1
"scaleY" => 1
"unit" => "EMU"
]
"alignment" => "BOTTOM_LEFT"
"blurRadius" => array:1 [▼
"unit" => "EMU"
]
"color" => array:1 [▼
"rgbColor" => []
]
"alpha" => 1
"rotateWithShape" => false
"propertyState" => "NOT_RENDERED"
]
"contentAlignment" => "MIDDLE"
"autofit" => array:2 [▼
"autofitType" => "NONE"
"fontScale" => 1
]
]
]
]
]
"slideProperties" => array:3 [▶]
"revisionId" => "uVl5gEdcOv8lvg"
"pageProperties" => array:1 [▶]
]get APIIf you have keen eyes, you're probably starting to see a correlation between the obfuscated save request via the frontend, and how the shape is represented via the get endpoint. My best guess is most of the integers are enums to actual keys (e.g. 4 = CreateShapeRequest?), wherein the nested arrays are the values from those keys.
For example: [0.6825, 0, 0, 0.6825, 191903, 14229]
This line to me is almost certainly related to scale, transform, etc. The order and the magnitude of the last two values are what confuses me the most, so this is an effort for another day.
Okay, back to the point:
presentation.get response right now. I can't simply pass it back to a different endpoint to generate this slide, nor will Google accept this schema in any other endpoint.Guess it's on me to do this myself; I need to convert the pageElements into batchUpdate requests.
foreach ($slide['pageElements'] as $pageElement) {
// determine what "kind" of element this is.
foreach($pageElement as $elementKind => $options) {
// loop through the elements until we find one that can identify the group
if(in_array($elementKind,self::elementKinds)) {
$this->parsePageElementToAction($elementKind,$pageElement);
}
}
}Here's where things get messy. In this case, the circle is of type shape, so now I need to generate requests for anything that someone could do with a shape:
// ...
case 'shape':
$this->CreateShapeRequest($pageElement);
$this->UpdateShapePropertiesRequest($pageElement);
$this->InsertTextRequest($pageElement);
$this->UpdateTextStyleRequest($pageElement);
$this->UpdateParagraphStyleRequest($pageElement);
$this->CreateParagraphBulletsRequest($pageElement);
break;In my case, I only expect that I'll need the first two: CreateShapeRequest and UpdateShapePropertiesRequest as there's no text within the shape.
There's some logic behind the scenes I've written here, so for the sake of this study, you can assume that all the translation is being done manually (since we know there's no native way to build up these batchUpdate requests.
Taking that slide above and passing it through my conversion layer, here's the generated requests:
{
"requests": [
{
"createShape": {
"objectId": "g2c5e29abb69_0_0bMiydqLYBn0", // origal + random 10 chars so its unique
"elementProperties": {
"pageObjectId": "SLIDES_API1926000256_0", // page ID I am inserting into
"size": {
"width": { "magnitude": 3000000, "unit": "EMU" },
"height": { "magnitude": 3000000, "unit": "EMU" }
},
"transform": {
"scaleX": 0.6825,
"scaleY": 0.6825,
"translateX": 4797575,
"translateY": 355725,
"unit": "EMU"
}
},
"shapeType": "ELLIPSE"
}
},
{
"updateShapeProperties": {
"objectId": "g2c5e29abb69_0_0bMiydqLYBn0", // must match the ID of the shape I created in the previous request
"shapeProperties": {
"shapeBackgroundFill": {
"solidFill": { "color": { "themeColor": "LIGHT2" }, "alpha": 1 }
},
"outline": {
"outlineFill": {
"solidFill": { "color": { "themeColor": "DARK2" }, "alpha": 1 }
},
"weight": { "magnitude": 9525, "unit": "EMU" },
"dashStyle": "SOLID"
},
"shadow": {
"transform": { "scaleX": 1, "scaleY": 1, "unit": "EMU" },
"alignment": "BOTTOM_LEFT",
"blurRadius": { "unit": "EMU" },
"color": { "rgbColor": {} },
"alpha": 1,
"propertyState": "NOT_RENDERED"
},
"contentAlignment": "MIDDLE",
"autofit": {}
},
"fields": "shapeBackgroundFill.solidFill.color.themeColor,shapeBackgroundFill.solidFill.alpha,outline.outlineFill.solidFill.color.themeColor,outline.outlineFill.solidFill.alpha,outline.weight.magnitude,outline.weight.unit,outline.dashStyle,shadow.transform.scaleX,shadow.transform.scaleY,shadow.transform.unit,shadow.alignment,shadow.blurRadius.unit,shadow.alpha,shadow.propertyState,contentAlignment"
}
}
]
}
batchUpdate requests.To clarify, there is no API, library, etc that tells you how to do this. I had to go through the process of studying the GET schema to see how the the slide is represented in JSON, then I had to logically convert that into the ~47 request types the Slides API defines as a part of a batchUpdate request.
So if you're studying the difference between these two, you can see that I'm effectively mapping all of the elements I see in the GET response into the batchUpdate request schema. And one pageElement, such as a shape with text, might result in 5+ requests for the shape, properties, text, style, paragraph, bullet points, etc.
Sidenote: Of the 47 request types, 10 of them are related to tables given how much detail can exist between rows and columns and the resulting formatting. Inserting a table itself could be hundreds of requests to get the formatting and text right!
Let's pass those two requests back to the API to generate a new slide. First, I'll use the presentation.create endpoint to create a blank presentation. Then I'll use presentation.batchUpdate with the above payload, and:
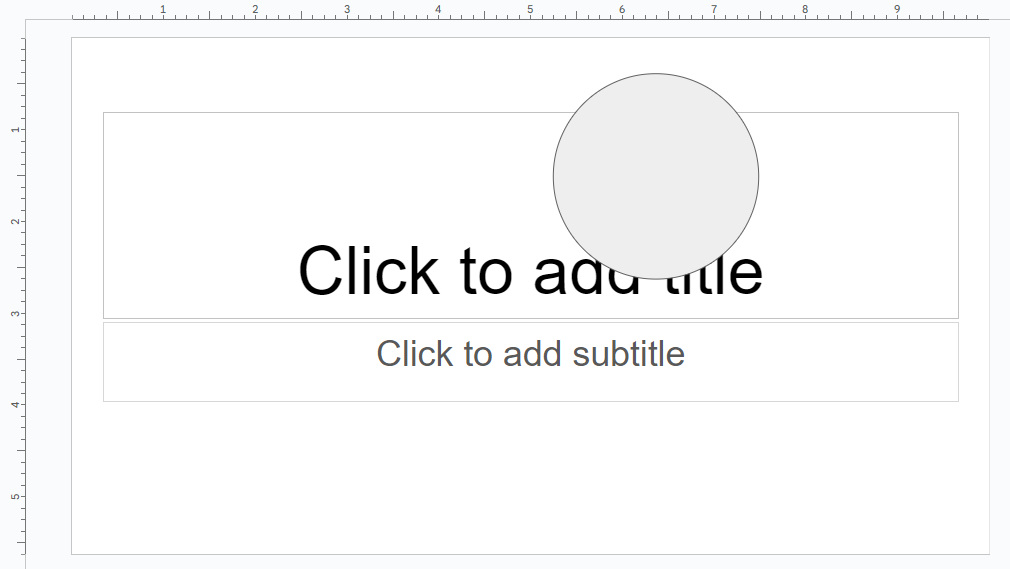
Turns out when you create a brand new presentation (presentations.create), since you can't pass any sort of template or master to it, you will always get these placeholders on the first slide. A workaround would be to create a new slide (via CreateSlideRequest) within the newly created presentation, then delete the initial slide with the placeholders on them. The ID of the first slide in any completely new presentation is always p, so you could reliably pass the DeleteObjectRequest alongside the CreateSlideRequest to make this reasonably seamless. Although there's some about needing to do 3 requests to get a truly blank presentation with one blank slide that feels silly.
Generally speaking, here's what we just did:
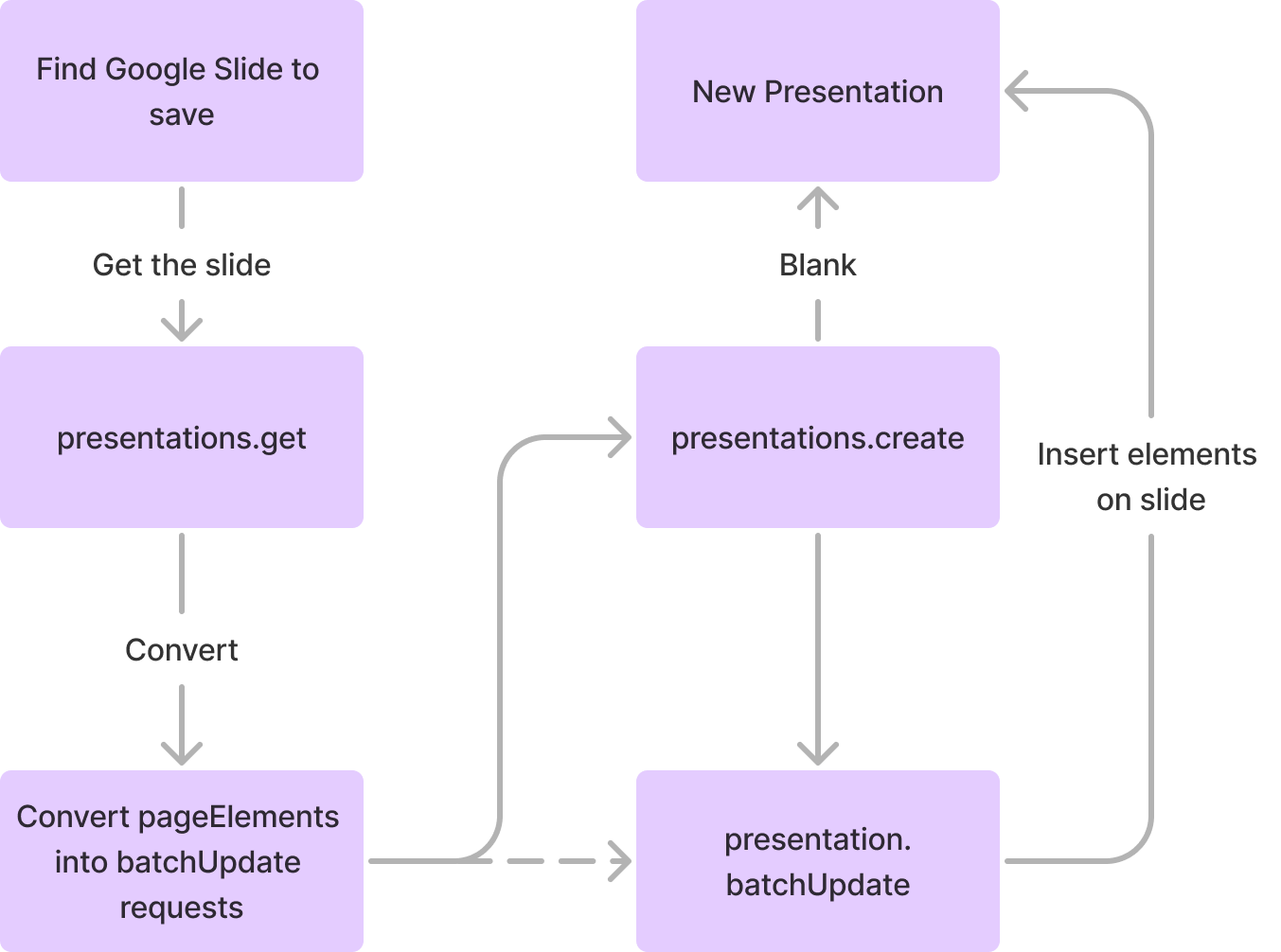
But hey, our gray circle is there! So that's a win.
Experiment 2: Simple Text
Let's repeat the above exercise and see where we land, this time using a text element instead of a shape.
Here's the input slide:
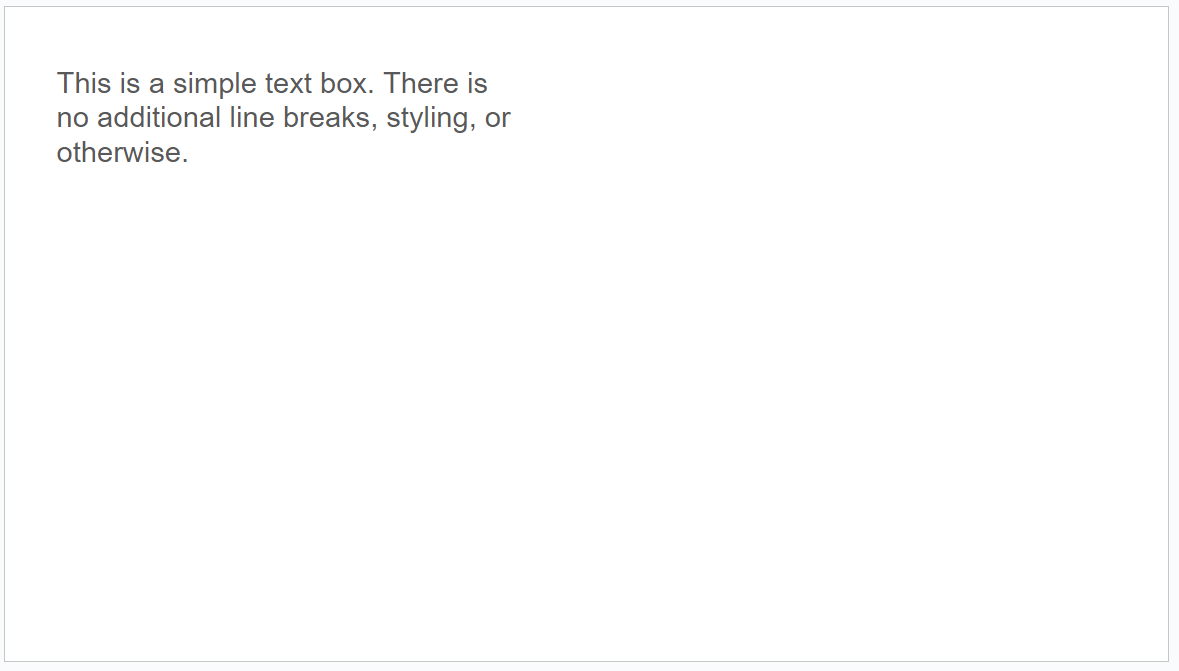
And the relevant snippet of the GET request (note that I'm using GET interchangeably with the presentations.get method):
...
"shape": {
"shapeType": "TEXT_BOX",
"text": {
"textElements": [
{
"endIndex": 86,
"paragraphMarker": {
"style": {
"lineSpacing": 100,
"alignment": "START",
"indentStart": { "unit": "PT" },
"indentEnd": { "unit": "PT" },
"spaceAbove": { "unit": "PT" },
"spaceBelow": { "unit": "PT" },
"indentFirstLine": { "unit": "PT" },
"direction": "LEFT_TO_RIGHT",
"spacingMode": "COLLAPSE_LISTS"
}
}
},
{
"endIndex": 86,
"textRun": {
"content": "This is a simple text box. There is no additional line breaks, styling, or otherwise.\n",
"style": {
"backgroundColor": [],
"foregroundColor": {
"opaqueColor": { "themeColor": "DARK2" }
},
"bold": false,
"italic": false,
"fontFamily": "Arial",
"fontSize": { "magnitude": 18, "unit": "PT" },
"baselineOffset": "NONE",
"smallCaps": false,
"strikethrough": false,
"underline": false,
"weightedFontFamily": { "fontFamily": "Arial", "weight": 400 }
}
}
}
]
},
"shapeProperties": {
...
},
"outline": {
...
},
"shadow": {
...
},
"contentAlignment": "TOP",
"autofit": { "autofitType": "NONE", "fontScale": 1 }
}
}First note here is the text still exists within a shape, although in this its a TEXT_BOX not an ELLIPSE like in our circle example.
...
Let's look at the simplified generated request, below. Main takeaways:
- Recreating this single textbox, with one identical (styling-wise) line of text requires 5 different requests:
createShape,updateShapeProperties,insertText,updateTextStyle,updateParagraphStyle. - The
insertText.textvalue includes the/nline break that was provided in theGETrequest. Is this going to hurt me in the future? More later...
{
"requests": [
{
"createShape": {
"objectId": "g2c5e29abb69_0_1tdL0RVf6q30",
"elementProperties": {
"pageObjectId": "SLIDES_API1665207381_0",
"size": { ... } ,
"transform": {
...
}
},
"shapeType": "TEXT_BOX"
}
},
{
"updateShapeProperties": {
"objectId": "g2c5e29abb69_0_1tdL0RVf6q30",
"shapeProperties": {
"shapeBackgroundFill": {
...
},
"outline": {
...
},
"shadow": {
...
},
"contentAlignment": "TOP",
"autofit": {}
},
"fields": { ... } ,
}
},
{
"insertText": {
"objectId": "g2c5e29abb69_0_1tdL0RVf6q30",
"text": "This is a simple text box. There is no additional line breaks, styling, or otherwise.\n",
"insertionIndex": 0
}
},
{
"updateTextStyle": {
"objectId": "g2c5e29abb69_0_1tdL0RVf6q30",
"style": {
"backgroundColor": {},
"foregroundColor": { "opaqueColor": { "themeColor": "DARK2" } },
"bold": false,
"italic": false,
"fontFamily": "Arial",
"fontSize": { "magnitude": 18, "unit": "PT" },
"baselineOffset": "NONE",
"smallCaps": false,
"strikethrough": false,
"underline": false,
"weightedFontFamily": { "fontFamily": "Arial", "weight": 400 }
},
"textRange": { "startIndex": 0, "endIndex": 86, "type": "FIXED_RANGE" },
"fields": { ... },
}
},
{
"updateParagraphStyle": {
"objectId": "g2c5e29abb69_0_1tdL0RVf6q30",
"style": {
...
},
"textRange": { "startIndex": 0, "endIndex": 86, "type": "FIXED_RANGE" },
"fields": { ... }
}
}
]
}batchUpdate request schema for this simple text slide.And here's what comes back generated:
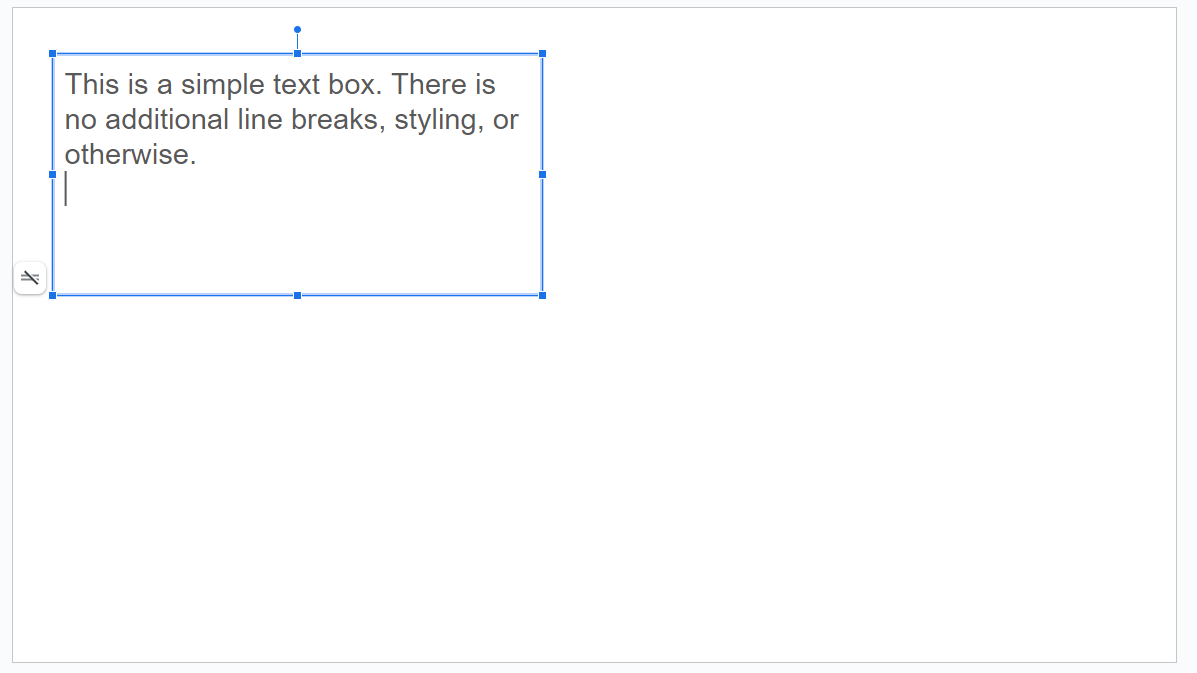
Looks great, however I see that extra line break in there. It's harmless in this case, but you can start to imagine how multiple lines of text with actual line breaks, different styles, idents, etc. might struggle to be recreated properly. Let's explore that on the next one.
Experiment 3: Textboxes, Text in shapes, and that pesky line break
Here's my starting point this time.

I'll spare you the details this time, but it's the same process I'm following:
presentation.getto get the JSON object of the slide that I created manually- Convert said object into
batchUpdaterequests - Send
batchUpdaterequests (133 in this case) to the API to recreate the slide in a new presentation
Results:

Pretty good, right? Looks like there's a little difficulty with the indent and the glyph for the extra bullets. The indent working for the second one but not the first is peculiar. In that I mean that I successfully defined how indents are set, but it was seemingly ignored on the first line. That's probably an error on my part, so we'll park that.
...
Let's move on to text in shapes. Say you've got 4 chevrons (the API would actually call this a HOME_PLATE shape) with text nicely centered (vertically) and left aligned. I also changed the font to Poppins, size 6. Same exercise as before:
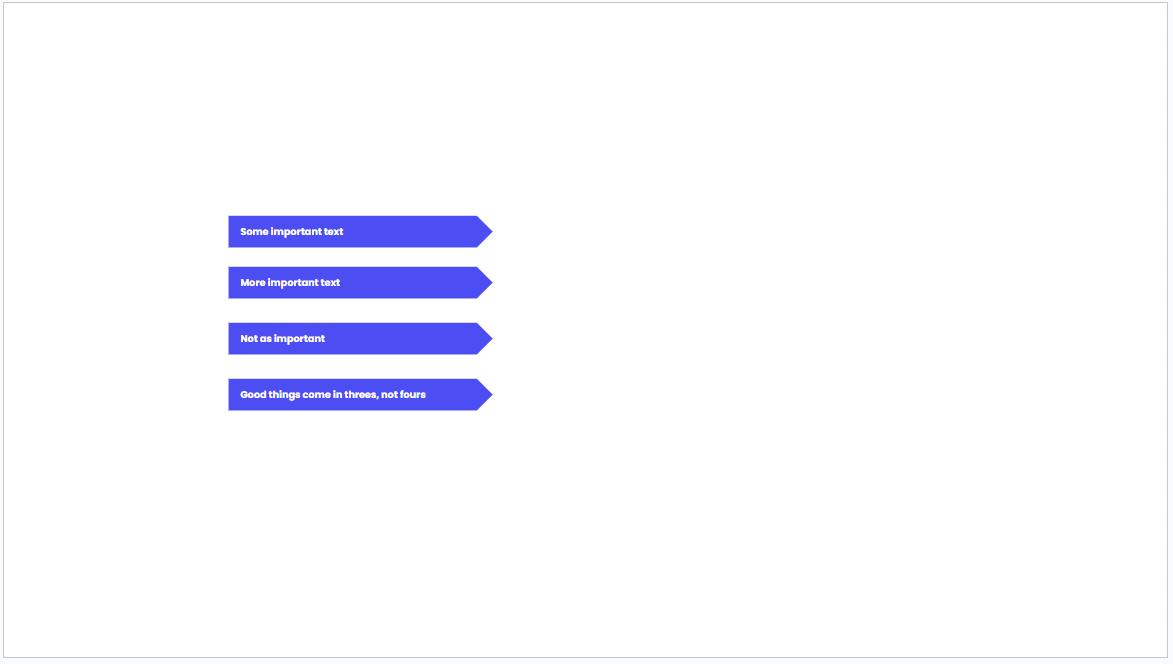
This time each of our chevrons have the text shifted up materially. What happened?

The short answer is we've got an additional line break at the end of every element. More interestingly, the font and size were seemingly reset back to Arial, 14 pt.
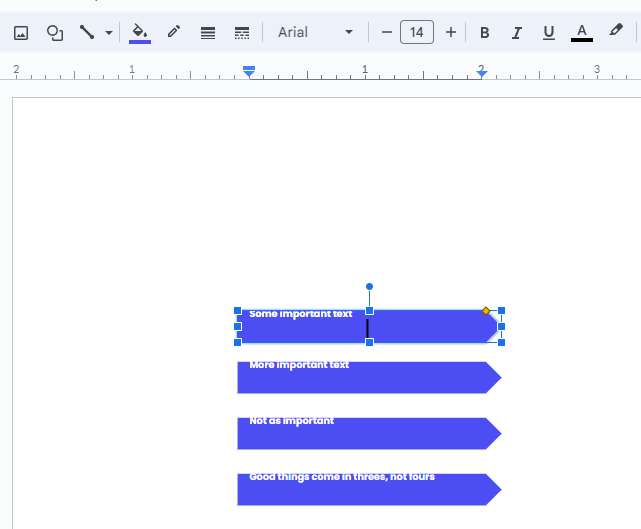
We can look back at the raw object JSON, generated by Google:
// ...
"textElements" => array:3 [▼
0 => array:2 [▼
"endIndex" => 20
"paragraphMarker" => array:1 [▼
"style" => array:9 [▶]
]
]
1 => array:2 [▼
"endIndex" => 19
"textRun" => array:2 [▼
"content" => "Some important text"
"style" => array:11 [▶]
]
]
2 => array:3 [▼
"startIndex" => 19
"endIndex" => 20
"textRun" => array:2 [▼
"content" => "\n"
"style" => array:11 [▶]
]
]
]
//...GET requestMy takeaway:
batchUpdate method by any translation.Fine I guess, I can fix this in my translation step. My hypothesis is that since I would never need to insert any text after the last element of a shape, then even if the object JSON of the slide has +1 index lengths on all instances of text, it shouldn't matter since I never need to insert there.
// if the last textElement is a blank (because a linebreak was trimmed), then skip
if($textElement === end($pageElement['shape']['text']['textElements'])) {
if (trim($textElement['textRun']['content']) === '') continue;
}
// logic to build up batchRequest here...In full disclosure, this was some trial and error. My strong belief from the beginning that was the GET slide JSON was the source of truth and it shouldn't be manipulated in any way. If I kept it as-is, I get rogue line breaks. If I trimmed all line breaks, well then not only can I no longer represent a user purposefully using a line break, but then I run into an issue where my text indexes are off:
{
"error": {
"code": 400,
"message": "Invalid requests[38].insertText: The insertion index (76) should not be greater than the existing text length (75).",
"status": "INVALID_ARGUMENT"
}
}batchUpdate request.Experiment 4: All the shapes
This one is a bit personal to me. Most good slides typically use shapes and iconography as a way of telling a story on the slide. If you only ever had text, you'd miss out on a lot of ways that we make our content more digestible.
Here's my input:

"requests" => array:146 [▶] later, I got this:

No need to look for differences - they are identical! There's another 40 of so shapes defined with Slides... I'll double check those in the meantime, but my hypothesis is that it'll be fine if all of the above work as well as they did.
Let's up the ante with some custom drawn lines and shapes:
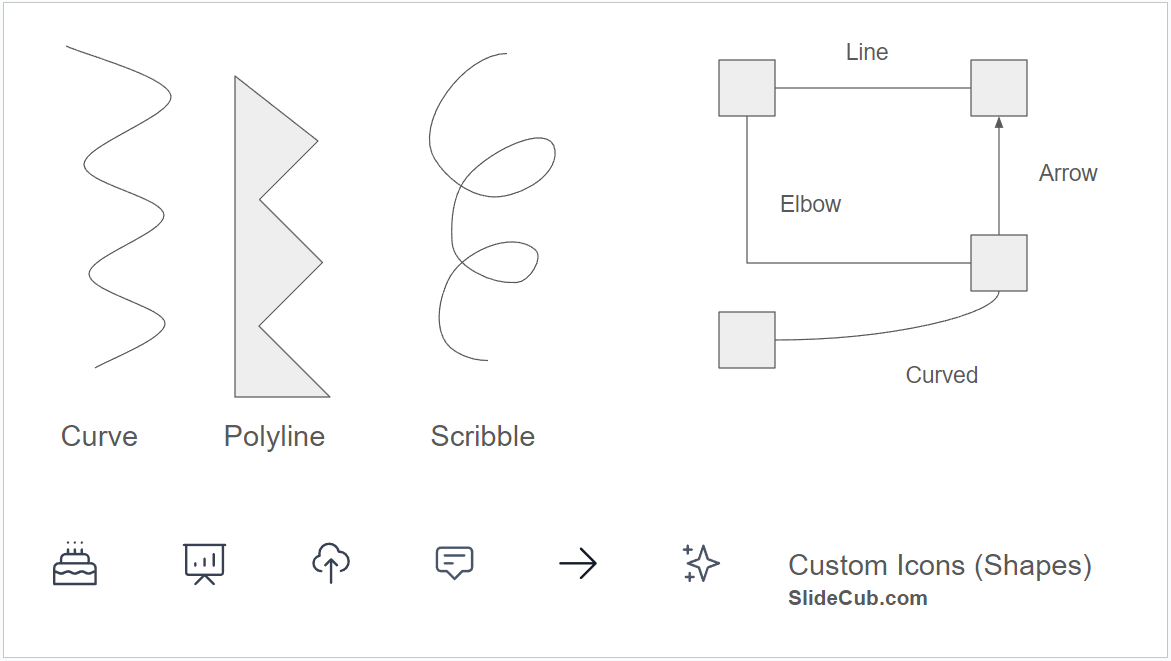
I threw in a few icons-as-shapes from SlideCub.com (if you're wondering why I've spent so much time with the GSlides API).
First off, if you study the documentation on shapes, you get this schema:
{
"shapeType": enum (Type),
"text": {
object (TextContent)
},
"shapeProperties": {
object (ShapeProperties)
},
"placeholder": {
object (Placeholder)
}
}There's maybe ~80 different shapeType's. This explains why in the experiment above, all of the shapes rendered correctly. There's one shapeType way at the bottom that says CUSTOM. You can probably imagine where I'm going with this, but first, let's just send the presentation.get generated JSON through the same conversion logic above and see what we get back from Google:
{
"error": {
"code": 400,
"message": "Invalid value at 'requests[65].create_shape.shape_type' (type.googleapis.com/google.apps.slides.v1.Shape.Type), \"\"",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.BadRequest",
"fieldViolations": [
{
"field": "requests[65].create_shape.shape_type",
"description": "Invalid value at 'requests[65].create_shape.shape_type' (type.googleapis.com/google.apps.slides.v1.Shape.Type), \"\""
}
]
}
]
}
}Isn't this interesting, looks like ShapeType as a null isn't allowed. Let's go find the raw object JSON and see how this object is defined:
22 => array:4 [▼
"objectId" => "g2c5e6e8ec58_0_112"
"size" => array:2 [▼
"width" => array:2 [▶]
"height" => array:2 [▶]
]
"transform" => array:5 [▼
"scaleX" => 0.0645
"scaleY" => 0.0645
"translateX" => 5346791.2475
"translateY" => 4268461.44
"unit" => "EMU"
]
"shape" => array:1 [▼
"shapeProperties" => array:5 [▼
"shapeBackgroundFill" => array:2 [▶]
"outline" => array:3 [▶]
"shadow" => array:8 [▶]
"contentAlignment" => "MIDDLE"
"autofit" => array:2 [▶]
]
]
]presentation.get for the above slide with custom shapesNotice anything... missing? shapeType isn't even defined. According to the documentation, this value isn't optional, yet nothing is provided. Is this another bug of the API? Odd that the API will define the shape for me, but then omit the type definition, which the resulting batchUpdate request requires. I'll have to hard-code any missing shapeType's to CUSTOM and see where that gets us.
The result?
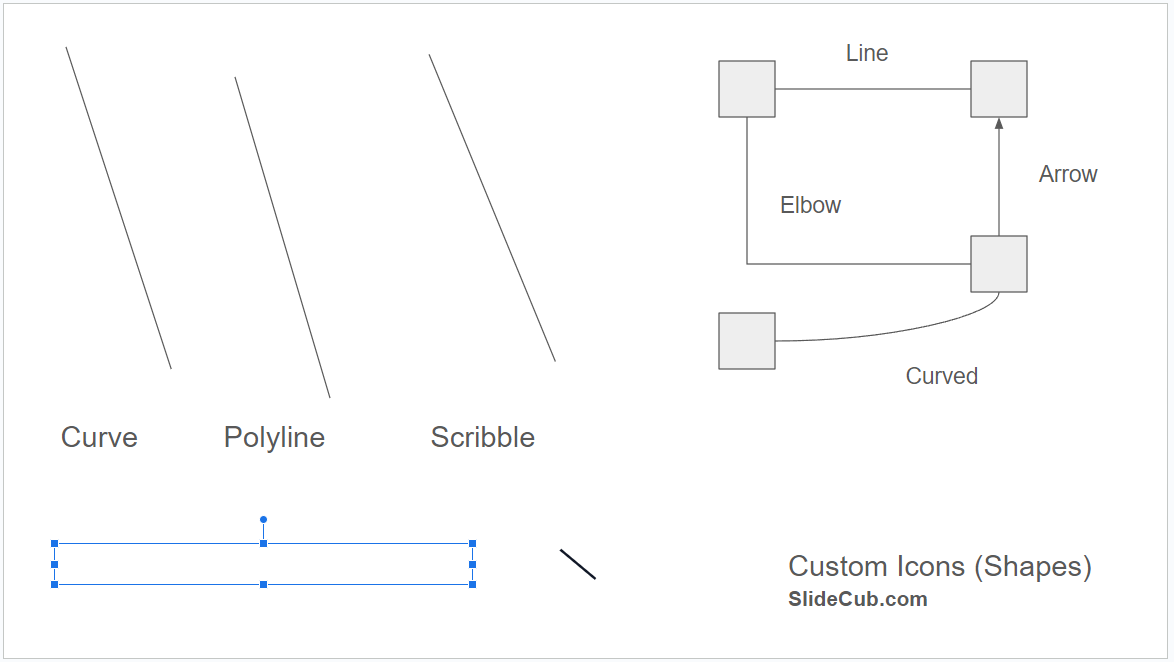
The takeaway:
All of the custom lines simply rendered a single line matching the bounds of the original. And all of the custom icons failed to render anything. A small piece of one of the icons did manage to appear, though I attribute this mostly based on how Google originally converted the SVG to a shape (via an uploaded PowerPoint).
Interestingly, the other icons still "exist" on the page, they just have no area. They have assigned border colors and fill colors and still nothing renders. As they have surface area, your cursor never can "grab" them, so you have to lasso the shapes and delete them. Perhaps a better solution is to cast any CUSTOM shape to a RECTANGLE or something that makes it obvious that there was/should be an icon here, rather than in this case where they largely are invisible.
...
One other gotcha - when you create a line, such as the ones I have above that are connected to the boxes, there are LineProperties for startConnection and endConnection. Therefore, if you create a new line that is meant to link between two newly created shapes, then you also now need to rewrite the LineProperties, which means I need to keep track of the objectID of the new shape (in my case, the few squares), so I can update the old references, or else the API will complain that you are trying to link a line to a shape on a different slide (or a shape that does not exist if you're creating an entirely new presentation).
Part 3: What's next
First and foremost, if you're associated with the Google Slides team, or perhaps even the Google Docs team (based on my understand that these share a lot of underlying logic), I'd love to pick your brain on how this was designed, roadmap, and any other interesting bits. If you're in San Francisco, let me know if you want to grab a coffee. ben @ this website .com
So what lead me down this rabbit hole? Icons.
I spent the first many years of my career firmly in the corporate "Microsoft" ecosystem. PowerPoint was a daily tool in my arsenal. Good iconography can make or break a slide. One strong plus of PowerPoint (vs GSlides) is that you can natively import SVG's and convert them to shapes. Google Slides, not so much:

There is a workaround however: insert the SVG into a PowerPoint slide then upload that slide to Google Slides. This process converts the SVG (likely treated as a native shape inside PowerPoint), into a shape in Google Slides. Now this is pretty tedious stuff if you want to have a full icon pack available to you.
So I built a better way: SlideCub. I can take advantage of the nature of a web app to simulate "duplicating" an icon such that I can insert onto the clipboard, the obfuscated steps to create the shape based on the SVG icon.
Here's how it works:
Want to try it out?
- Go to Slidecub.com/icons/heroicons
- Open a Google Slides presentation in another tab
- Select an icon from SlideCub
- Change to the presentation and Ctrl + V (Cmd + V on Mac) to paste.
I'm building out enhanced support for teams now, but if you put in your work email and it matches a company team (that allows direct signups), you'll be redirected to join that team. Always open to thoughts.
...
Lastly, I have a vision to develop a robust slide repository where you can save and create slides on demand. Instead of starting with your corporate template of 100 slides, why not pick and choose what you need from a custom collection. This is still very much in its infancy, and the above study is a reflection of my investigation into making this work. Here's a sneak peak at how it actually works:
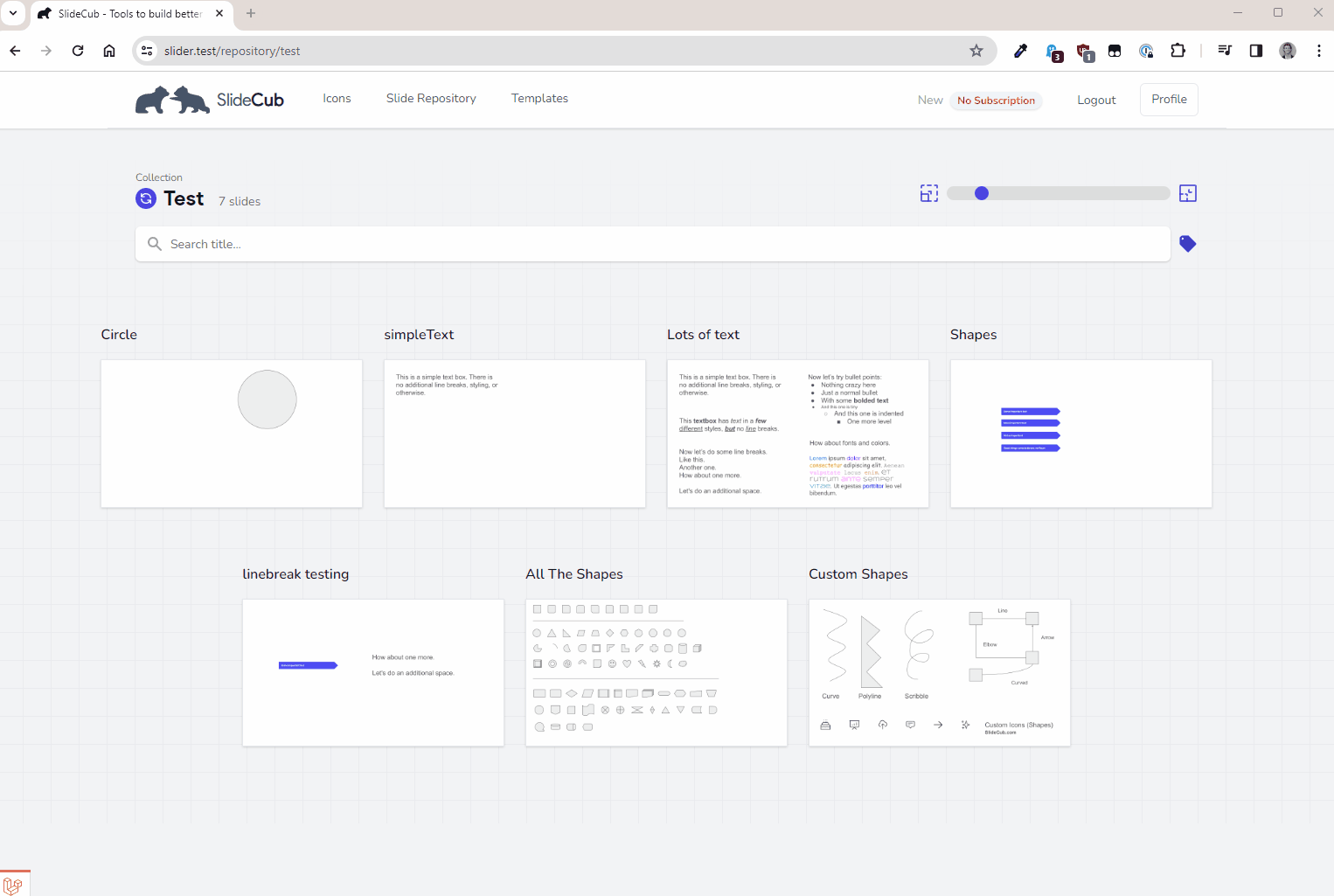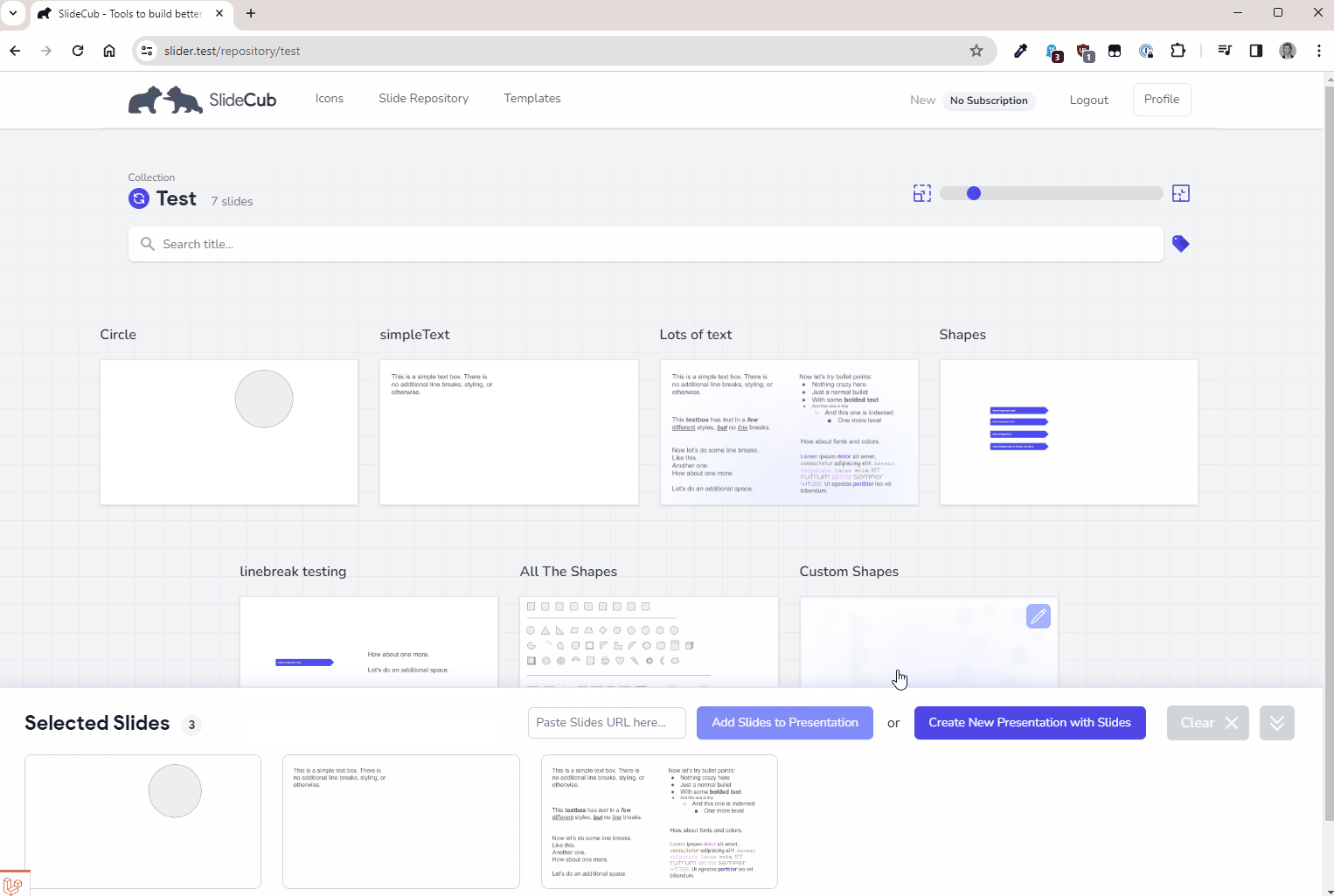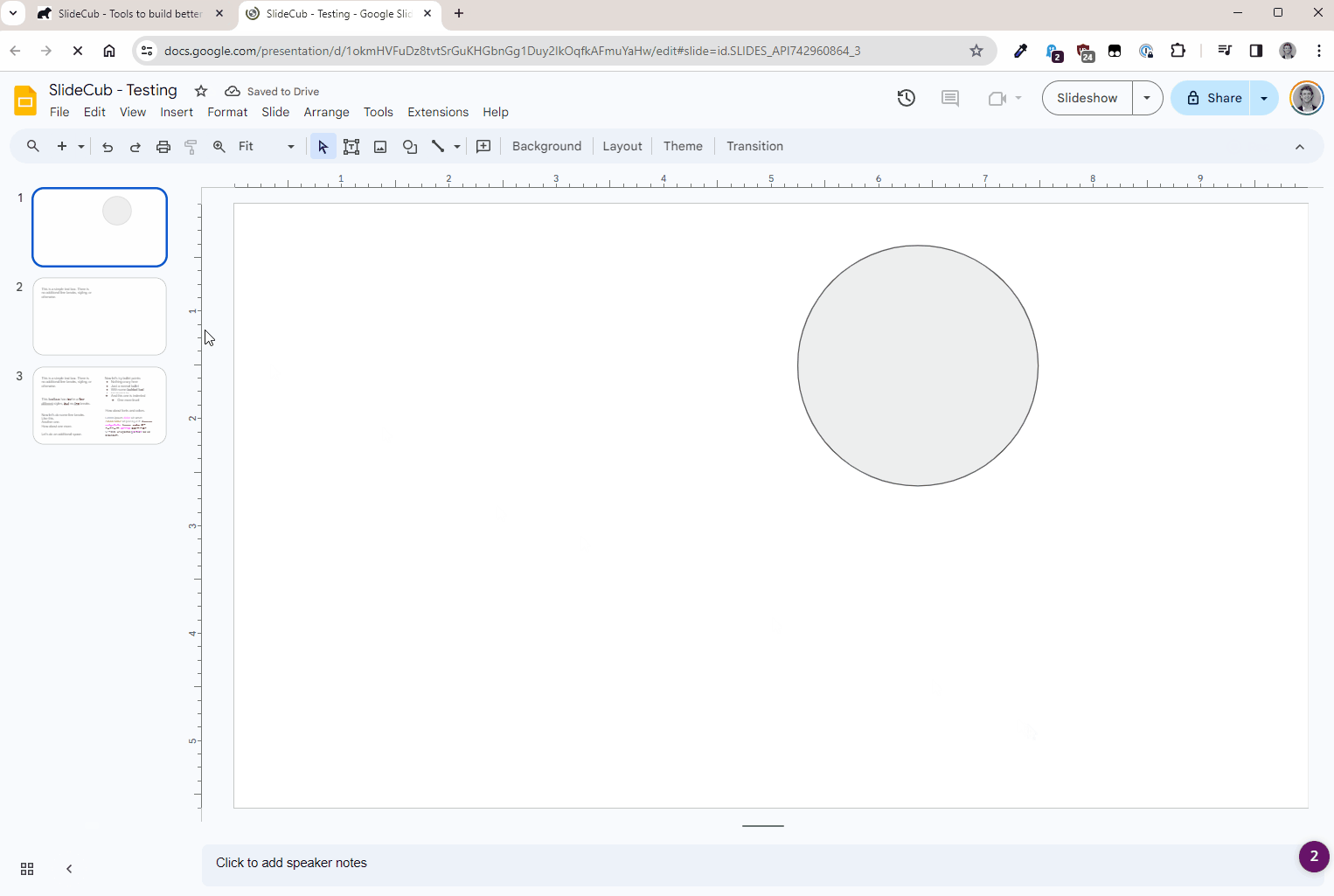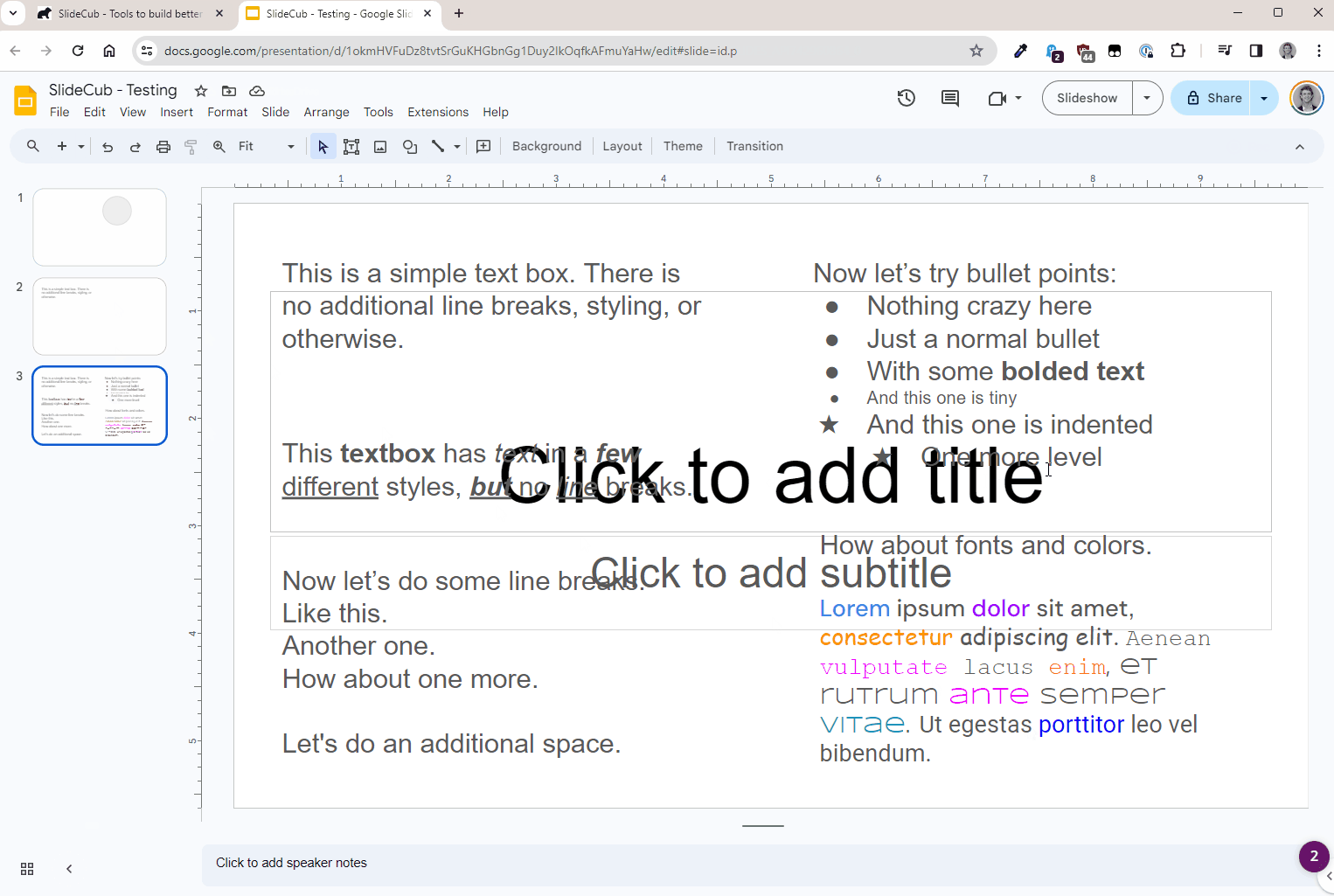
Everything you're seeing above is exactly what I did for each of the experiments:
- Save slides (via a bookmarklet) - not shown
- Access slides in a repository
- Select the slides you want
- Select "generate"
If you're interested in being a beta tester, please reach out: ben @ this website

Member discussion: